再会
与同学们的最后一次相见
再会了
与同学们的最后一次相见
再会了
在朋友的怂恿下看了初恋豚鼠
在感动过后彻底认识到了自己人生的失败
今天就继续努力吧
但是我们家是过农历的所以还没到(┬┬﹏┬┬)
发现好多动漫角色都是7月14生日啊


生日快乐ヾ(≧▽≦*)o
毕业了,和很多人见完最后一面,期待着夏天的改变,却还是无所事事的坐着
这就是我现在的样貌
到头来,还是什么都没发生
不过暂且,沉浸在这首歌里吧
毕竟前路还长
终于看完了第一集,来说说我的感想吧
感觉这部氛围是轻松愉悦,非常适合小朋友观看ヾ(≧▽≦*)o
第一集男二的印象最深刻,本来以为是经典的傲娇,结果是一位非常可靠,有时蛮搞笑的正常人(怎么有单位不提供咖啡啊done,结果自己就带了一个咖啡机😂
奥特曼的打戏蛮有新意的,我最喜欢的是室内的视角(虽然前几部也有过
没有从男主遇到奥特曼开始拍,搞得我还以为放在特别篇里了
op和ed都非常好听!
总而言之,如果能一直保持这个势头就好了,跑起来,优马!
准备照着重打一遍代码,不过是用tensorflow.js
持续更新。
首先先粗略的理解一下文本生成的原理吧,虽然非常幼稚…![]()
注意力:对应两个token之间的关系
文本生成:根据上个token预测下一个token
k,q,v:k与q相对应,v作为输入,输出v2,v2又作为下一个输入…
所以理论上,一层注意力也是能用来生成的,只要参数够大…
希望没有错的太离谱。
在github上发现了一个有趣的项目
transformer-tfjs
直接在浏览器里训练模型,太牛逼了,准备照着做…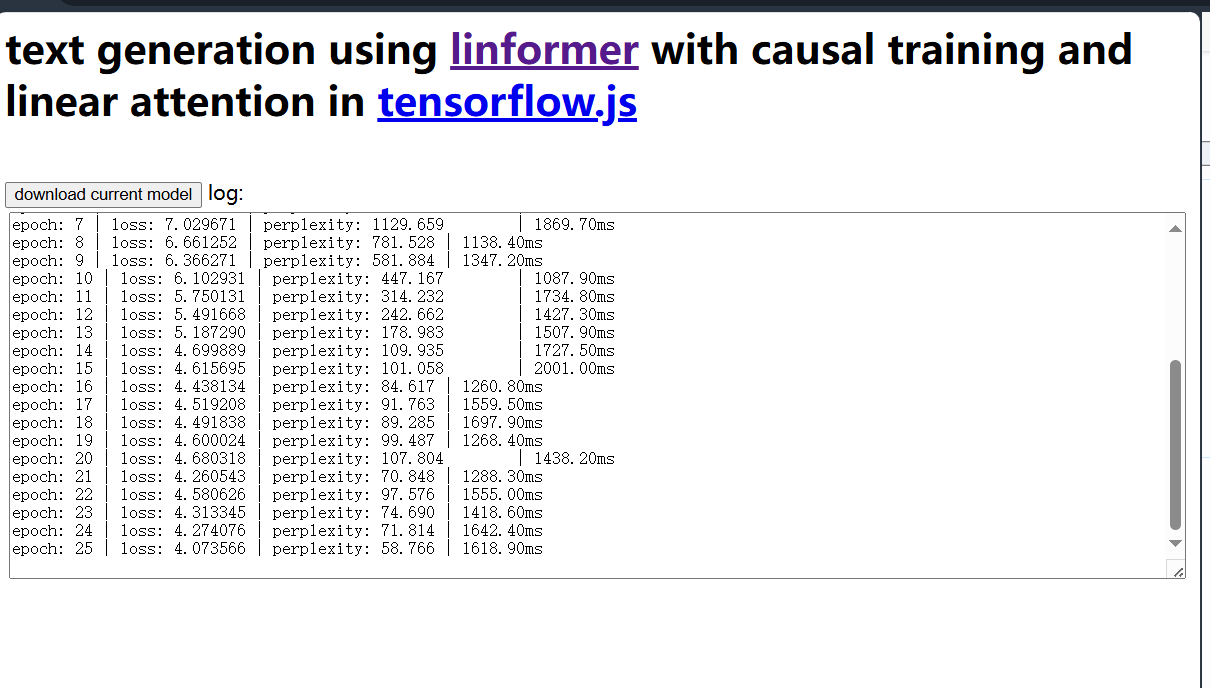
1 | tf.util.shuffle(data) |
最简单的,RMS_Norm归一化。
但我不是很懂mean()这个函数,沿着第1维和第2维好像都能出现结果。。。
(划掉)
而且出现了未完全归一化的结果…
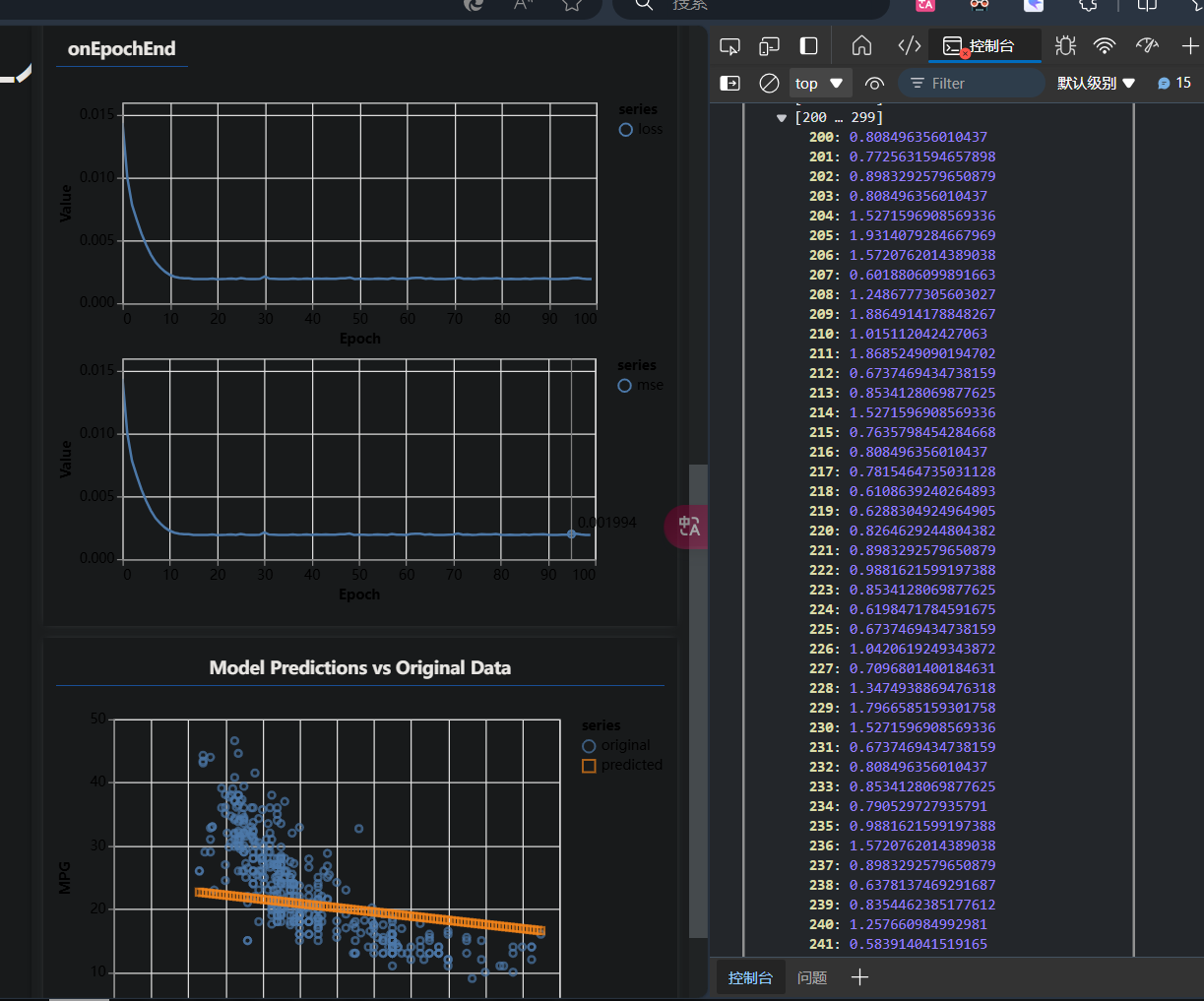
呃…大体上是完成了吧。(还是用简单点的ba…)
1 | //import * as assert from 'assert' |
用numjs和js-tiktoken实现编码,模仿prepare.py保存为二进制。
之前在bilibili看到一个简易的llm:
虽然没完全看懂,不过还是先试着运行一下。
不过问题来了,我没有显卡,用cpu训练又太慢。
于是就打算在coloab平台上训练。
将文件夹上传到谷歌硬盘,再在coloab中装载。
不知为何相对路径没有用,就用绝对路径了。(估计是我填错了)
先准备数据集,用了自带的.
运行train.py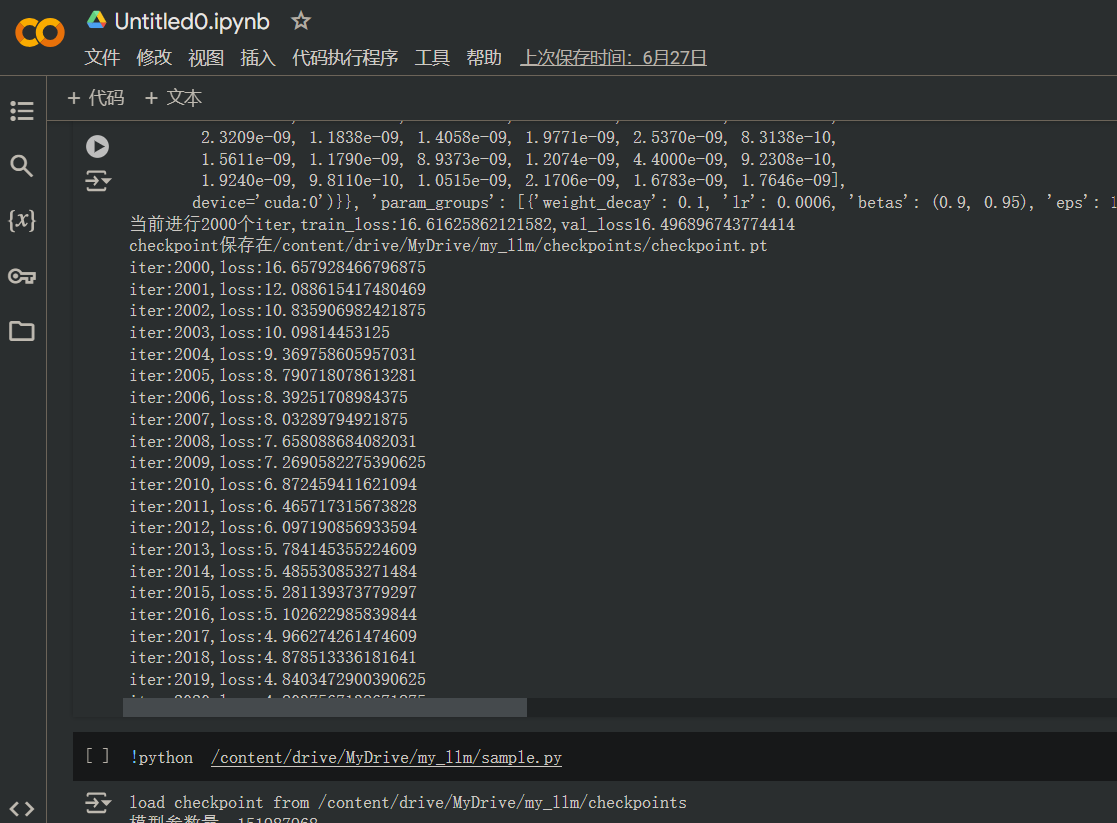
这里已经训练过两轮了
大小居然要1.7G…
运行sample.py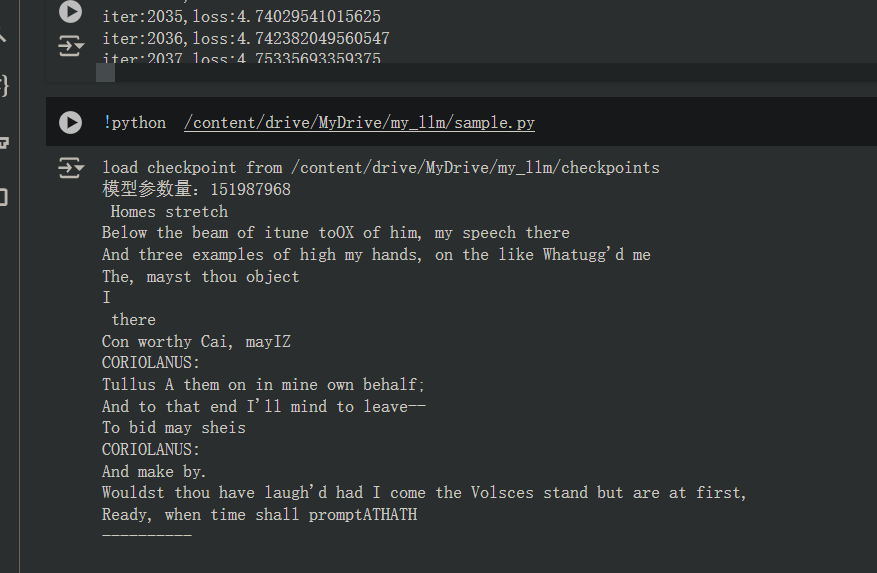
效果还不错。
之后:学习一下架构,继续削减参数,魔改网络。
保留下来作为纪念吧
Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.
1 | $ hexo new "My New Post" |
More info: Writing
1 | $ hexo server |
More info: Server
1 | $ hexo generate |
More info: Generating
1 | $ hexo deploy |
More info: Deployment
又是无意义的展开,我的未来…
会如何呢,真是期待啊
小时候看到的,绚丽多彩的世界